In this blog I share something I’ve been saying for a while now that people suggested might just be audacious enough to spark a conversation.
Plus — I explain why I’ve decided to help found another storage project — OpenEBS — and to become CEO of the underlying company, CloudByte, at a time in which venture capital funding to the space has declined (at least if you accept Rubrik and Cloudian and similar) funding as outliers :)).
TL;DR: the old storage industry is dying like many stagnant and declining IT sectors before it, killed through outdated business practices and architectures and the emergence of a new set of personas that have radically different requirements, expectations, and even tastes. The new architectures and business models already exist — though they are unevenly distributed.
I lay the story out in three points. I keep it brief and link to underlying technical resources w/ code and demos via those links for those that are interested. Please discuss below and/or at: @epowell101. Better yet, click here to be invited to our Slack channel: https://openebsslacksignup.herokuapp.com
Storage is dead? How so?
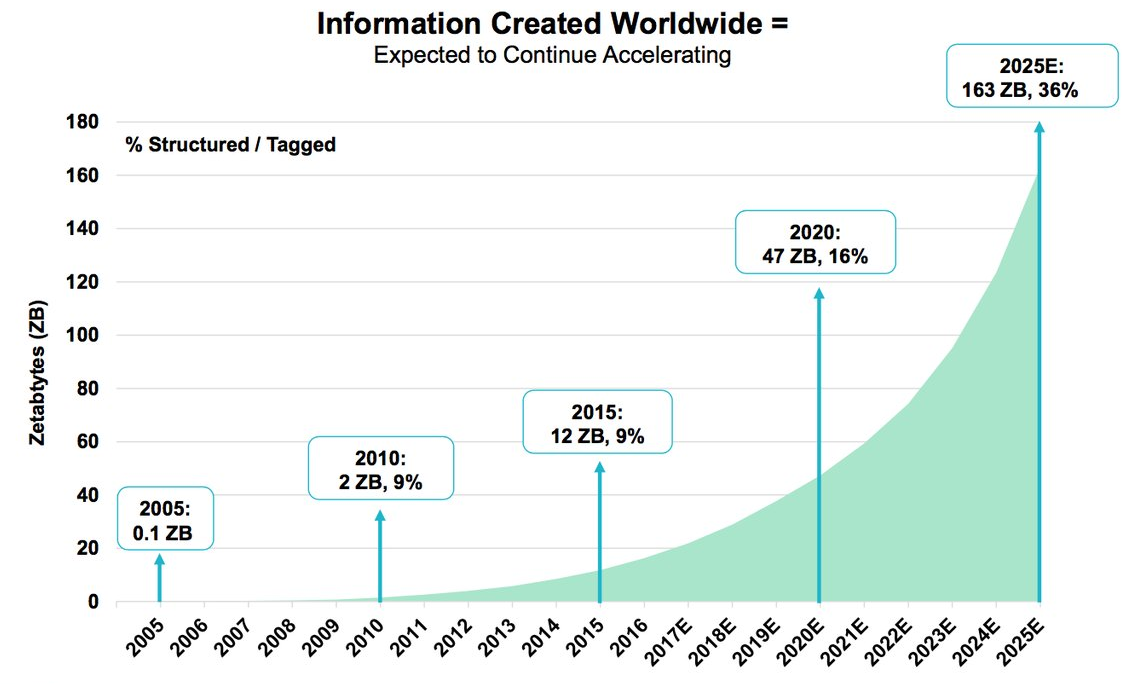
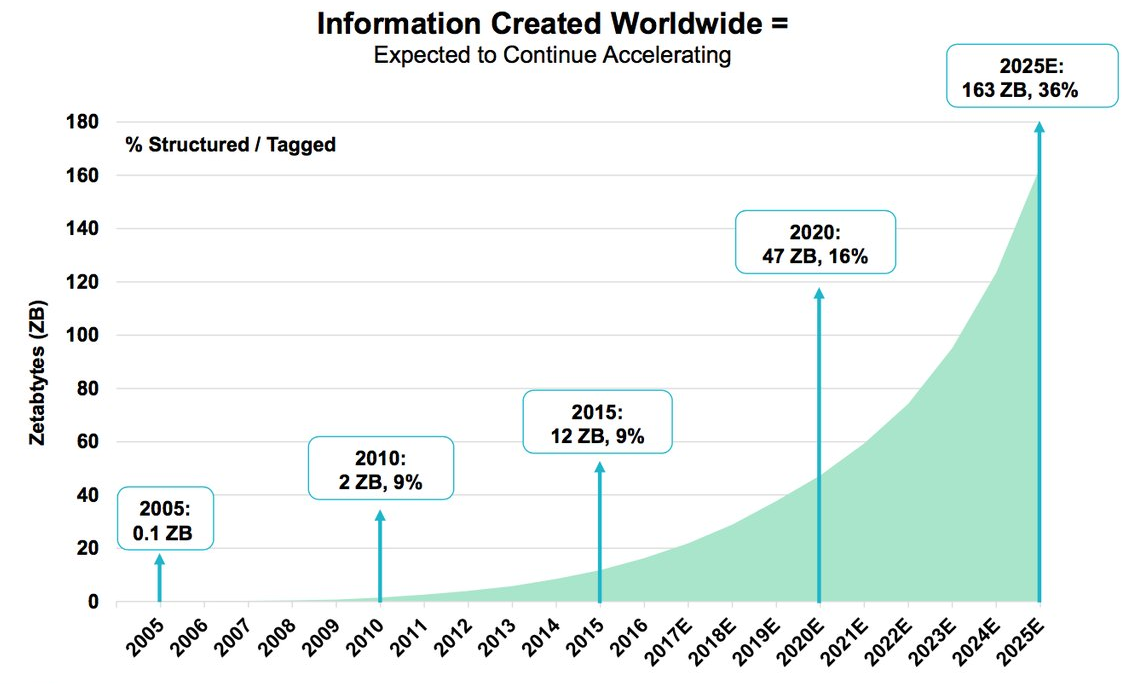
On the one hand, massive data growth continues. It is easy to look at a graph like the one above showing ongoing exponential growth in data created and conclude that the funding winter that has hit storage is just another irrationality of the venture market. Perhaps it is like 2006–2008 when too many of the top enterprise technology VCs had a couple of walking dead storage companies in in their portfolio and wouldn’t or couldn’t take on new investments.
And many thanks to Mary Meeker and Kleiner Perkins for her annual reporton trends for the graph.
Cloud
On the other hand, cloud. The major cloud vendors are a) truly major and b) see storage as a way to control customers.
To the ‘truly major’ point — the three largest cloud providers are some of the largest companies the world has ever seen. Those of us that remember the power of WinTel in the 90s and early 2000s need to remember that this time is different in part because the companies are massively more wealthy thanks in large part to having business models that transcend technology.
To the ‘control customers’ point — data gravity exists. And it is further leveraged by cloud providers making it free to transfer data to them and rather expensive to get it back.
Which brings us to DevOps and cross cloud services…
DevOps and cross cloud services
As I learned from my experience as a co-founder and CEO of StackStorm, DevOps is a radically better way of building and running software — as well as being a cultural movement.
And while there are many, many characteristics of what constitutes a “DevOps environment” — one important aspect as I see it is that the intent of the developer can be fully manifested by the underlying infrastructure and related services.
And a second aspect is that many capabilities are consumed by the applications and the application developers as services. This fits with the use of micro services as well, of course.
Last but not least, DevOps is a culture and a set of practices that, as demonstrated by the story of the crucial book the Phoenix Project, is motivated in part by a realization of how broken, slow, dysfunctional, unfair, and brittle, proprietary IT systems and IT operations traditionally have been. From this perspective, applying infrastructure as code in part to insure cross team transparency and blameless postmortems and so forth are not just examples of useful techniques — they are manifestations of the values of a better culture.
One strength of clouds like AWS is that they enable you to consume storage in a DevOps friendly way — your orchestration or other automation can deal with the provisioning and management (or can rely on the solutions provided by the cloud provider) so that intent can flow from the application through the infrastructure; in addition, the infrastructure is there to be consumed dynamically, via APIs. Unfortunately the cloud providers themselves have become the new proprietary, which makes some in the DevOps world a bit uncomfortable as in the past lock-in was used by proprietary vendors to maximize their own prices at the expense of their customers. Kubernetes especially offers a chance to keep the wiring free from the cloud providers, hence providing some hope of avoiding lock-in.
Uhh, huh — and OpenEBS?

In short, the highest level vision for OpenEBS is one in which the DevOps friendly aspects of running storage in the cloud is now available on premise and across your clouds, thus freeing you from vendor lock-in much in the way that Kubernetes helps you avoid the risk of locking yourself in through the use of cloud service specific wiring and workflow.
What if your developers and devops teams could orchestrate your storage controllers just like other containers? How much more productive could they be?
And what if that set of storage services allowed you to treat your stateful workloads on containers much like the ephemeral containers that have proliferated?
And what if your storage and CIO teams were able to establish policies that governed your data without impeding the agility that was your purpose in moving towards containers and DevOps in the first place?
Last but not least, what if, having tooled your environment to work with Amazon it just worked when you added the on-premise and cross cloud OpenEBS? Wouldn’t this limit your lock-in with any one cloud vendor?
OpenEBS remains early. Today we are at release 0.3 and are just starting to be used by enterprises like Cap Gemini and others to deliver storage for stateful workloads on containers.
I’m back into the storage industry because I’m sure that OpenEBS has a good chance to allow storage to slip into the background and “just work” to support the incredible boosts in agility delivered by DevOps.
A bunch of us imagined a better storage industry — one more software like, one that eliminated vendor lock-in — back in the 2008 / 2009 time frame. Instead, we got some kick ass flash and quite cool hyperconverged solutions PLUS, mostly, AWS just working (well enough) with a far better business model and ability to scale.
So vendor lock in remained a problem. And storage far too often remains the bottleneck that slows down the good stuff, including the shift of real workloads onto containers.
OpenEBS is going to fix all of that and make storage and related storage services something you use to free yourself from lock-in while boosting your operational agility. Game on!
You can learn more about today’s release of OpenEBS 0.3 from our COO and co-founder’s blog here. I think you’ll agree, what’s possible now reinvents storage fundamentally — with your help we’ll turn this project into a company and a complete solutions that we can all rely on.
Other resources include demos of OpenEBS working seamlessly with Kubernetes and interesting stateful workloads including PostgreSQL and the Spark notebook Jupyter in our demo repo here.
Blog post by Evan Powell, CEO Cloudbyte/ OpenEBS